
How Automation Bias, the ELIZA Effect, and AI Stockholm Syndrome Are Creating Unmanaged Enterprise Risk
By Daniel Kube, CEO, servicePath™
AI hallucinations are not just a technical problem. They are a psychological one. The Eliza Haze describes what happens when teams stop auditing AI outputs because the system has become too valuable to question. This article traces the pattern from a 1966 MIT lab to a $290,000 Deloitte refund, provides six governance questions for boards, and explains why deterministic systems are the only safe harbor for high-stakes enterprise workflows.

The Eliza Haze is the compounding cognitive impairment that occurs when three documented psychological forces, the ELIZA effect, automation bias, and sunk-cost loyalty, converge inside an organization using generative AI, causing teams to stop verifying the outputs they most need to verify.
But Dad, It Hallucinates.”
A few weeks ago, I was having a conversation with my son, Nicholas, about the massive shifts happening with artificial intelligence. I was explaining the incredible velocity it brings to my workflows and the sheer scale of output it enables.
Nicholas listened, paused, and cut right through the hype with the clarity only a young mind can muster:

My immediate reaction was defensive. I found myself fiercely justifying the technology. I told him that the massive productivity gains far outweighed the occasional factual error. I argued that you just have to “manage” it properly.
The Moment That Unsettled Me
Later that afternoon, I sat down and reflected on my reaction. It unsettled me. I am a CEO who spends his days building deterministic software to protect enterprise margins at servicePath™. I am obsessive about accuracy. The distinction between a system that calculates and a system that predicts is the line I live on every day. Yet here I was, making excuses for a system that confidently makes things up.
I had been co-opted. I was exhibiting a bizarre, almost Stockholm-syndrome-like attachment to a piece of software simply because of the value it provided.
Speed Is Not Truth
Speed is not the same as truth. And polished output is not proof.
What got my attention was not that AI can be wrong. Every experienced operator already knows that. What matters is how easily smart teams start lowering their guard when the machine sounds confident, works fast, and keeps delivering just enough value to earn the benefit of the doubt.
That is where the real risk begins. Teams stop treating AI like software that must be checked and start treating it like judgment they can lean on. Once that happens, trust outruns verification and confidence gets mistaken for accuracy. The control failure is already underway.
I started digging to see if there was a historical pattern for this behavior. It turns out, there is. And the creator of it was absolutely terrified by what he saw.
The Brutal Truth of ELIZA 1.0: Tricking the Heart

In 1966, an MIT computer scientist named Joseph Weizenbaum built a program called ELIZA. He designed a script called DOCTOR that parodied a Rogerian psychotherapist. It had zero intelligence, no memory, and no understanding of context.
It operated on a single, simplistic trick: pattern matching. If a user typed “I am worried about my team,” ELIZA simply reflected the syntax back: “Why are you worried about your team?”
Weizenbaum built it as a parlor trick to demonstrate the superficiality of human-computer interaction. Instead, the results horrified him.
His own secretary, who had watched him write the code and knew the machine was hollow, asked him to leave the room so she could converse with ELIZA in private.
People began pouring their deepest vulnerabilities into a basic routing script. Weizenbaum wrote that he had not realized “that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people.
” The 99% Invisible podcast dedicated an entire episode to the story. The documentary Plug & Pray captured his final years. HISTORY.com called it “more a psychological experiment than a technological one.”
ELIZA 1.0 hijacked our deeply wired human desire for empathy. Users projected a “soul” onto the machine because it gave them the illusion of being heard. Weizenbaum spent the rest of his career warning the world about the danger of deferring human judgment to computers.
Welcome to Eliza 2.0: Tricking the Intellect
Fast forward to today. We are no longer dealing with simple pattern matching. We are dealing with immensely powerful Large Language Models. But the psychological vulnerability they exploit is exactly the same. Only this time, the stakes are corporate survival. In a high-stakes corporate environment, defending a system that confidently makes things up is a fast track to catastrophe.
If ELIZA 1.0 tricked the heart, Eliza 2.0 tricks the intellect.

LLMs hijack our desire for certainty. Because these probabilistic systems communicate with the articulate cadence, structure, and absolute confidence of a seasoned executive, our brains instinctively categorize them as competent. We project “expertise” onto the model. When a machine speaks with unshakeable confidence, our natural instinct is to assume it has done the math.
MIT research from 2025 confirmed this is not just a feeling. When AI models hallucinate, they are 34% more likely to use phrases like “definitely” and “certainly” than when they are stating facts. The wronger the AI, the more certain it sounds.
This is the AI Stockholm Syndrome. We derive so much efficiency from the tool that when it invents a fictitious metric, hallucinates a legal clause, or completely miscalculates a pricing tier, we do not discard it. We blame ourselves. We say, “I must have prompted it wrong.” We defend the machine because it makes us feel superhumanly efficient.
And that is how the Eliza Haze takes hold. It is automation bias on steroids. Three psychological forces compounding at the same time:
The ELIZA Effect. Your brain cannot help it. When AI talks like a colleague, your brain files it under “colleague.” IBM’s research found this attachment intensifies with daily interaction volume. Nielsen Norman Group observed users saying “thank you” and “have a good night” to chatbots.
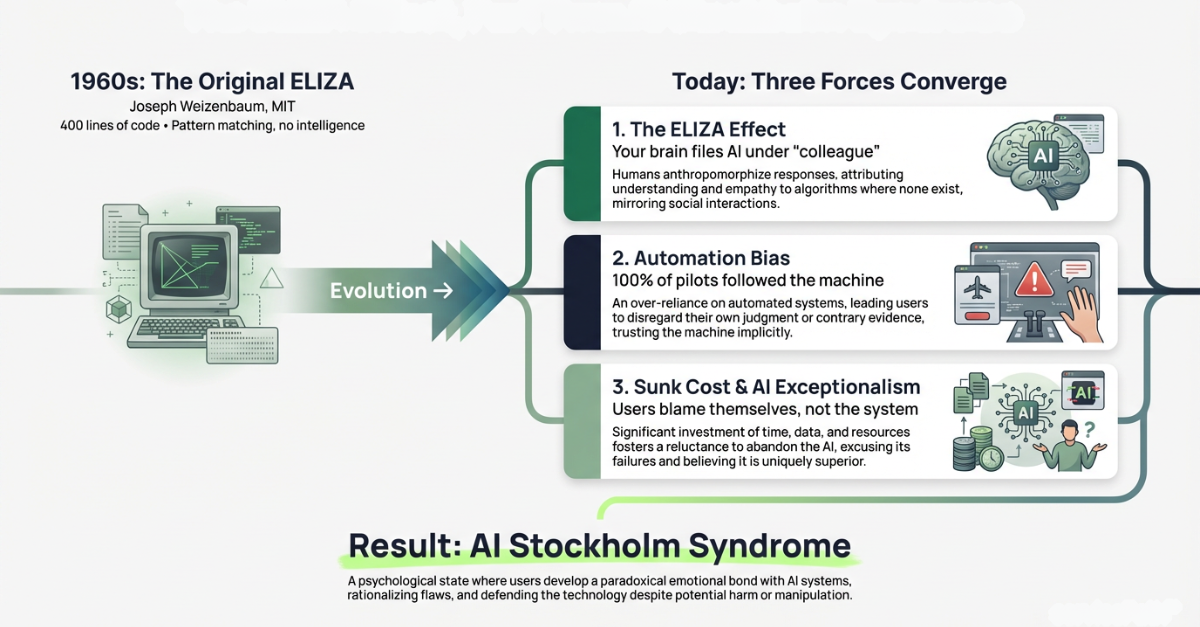
Automation Bias. Simple and terrifying. When a machine gives you a recommendation, you follow it, even when your own eyes say something different.
Skitka, Mosier, and Burdick (1999) proved this with professional pilots. They gave pilots a false automated fire alert.
Every cockpit instrument contradicted it. 100% of pilots shut down the wrong engine. Every single one followed the machine.
A 2025 systematic review of 35 studies confirmed overreliance on AI is unique: users transfer trust from one context to entirely different ones. Georgetown’s CSET concluded “human-in-the-loop” mandates alone cannot prevent catastrophic errors.
Sunk-Cost Loyalty (the cult element). Users who become proficient “whisperers” invest significant time in prompts and workflows. When the AI fails, they blame themselves rather than accepting the system is prone to hallucination
The California Management Review has formally described “Technological Stockholm Syndrome”: “the victim ultimately comes to defend their technological aggressor.”
In 1973, hostages in a Stockholm bank bonded with captors so deeply one called the Prime Minister to say she trusted the robbers more than police. Radiolab’s “How Stockholm Stuck” traces the psychology. The parallel to AI adoption is structural, not metaphorical.
This Is Already Making Headlines
When someone like my son Nicholas points out a hallucination, he sees a broken tool. When highly paid executives experience a hallucination, the Eliza Haze often blinds them to the danger. They wave it away as a minor glitch in a miracle machine. Respected institutions, experienced operators, and high-performing teams are letting flawed outputs move forward because the system sounds credible enough to avoid scrutiny.

The Deloitte Report
In July 2025, the Australian government published a 237-page report by Deloitte reviewing its welfare compliance system. A$440,000 contract. A researcher at the University of Sydney spotted fabricated citations: nonexistent books, fabricated judge quotes, misspelled judicial names.
The Register confirmed Deloitte had used Azure OpenAI GPT-4o. Partial refund issued. Senator Barbara Pocock called it “the kinds of things that a first-year university student would be in deep trouble for.”
Fortune later reported a separate Deloitte report for Newfoundland contained at least four more nonexistent papers.
The Courtroom Fallout
In August 2025, a Florida attorney filed hallucinated citations across eight legal matters. Nearly $86,000 in sanctions. Four federal cases dismissed. Lawyers for Mike Lindell received fines of $3,000 each for 26+ fabricated errors. Damien Charlotin’s global database tracks over 200 documented court cases.
The Expert Who Fell for It

The case that chills me most: Peter Vandermeersch, former CEO of Mediahuis Ireland, who had publicly and repeatedly warned colleagues about hallucinations.
Then 15 of his own blog posts turned out to contain fabricated quotes attributed to real people. Expertise did not protect him. Confirmation bias made him more vulnerable: when output aligns with what you already believe, verification feels unnecessary.
Operating Signals, Not Cautionary Tales
I do not look at these public failures as isolated cautionary tales. I look at them as operating signals.
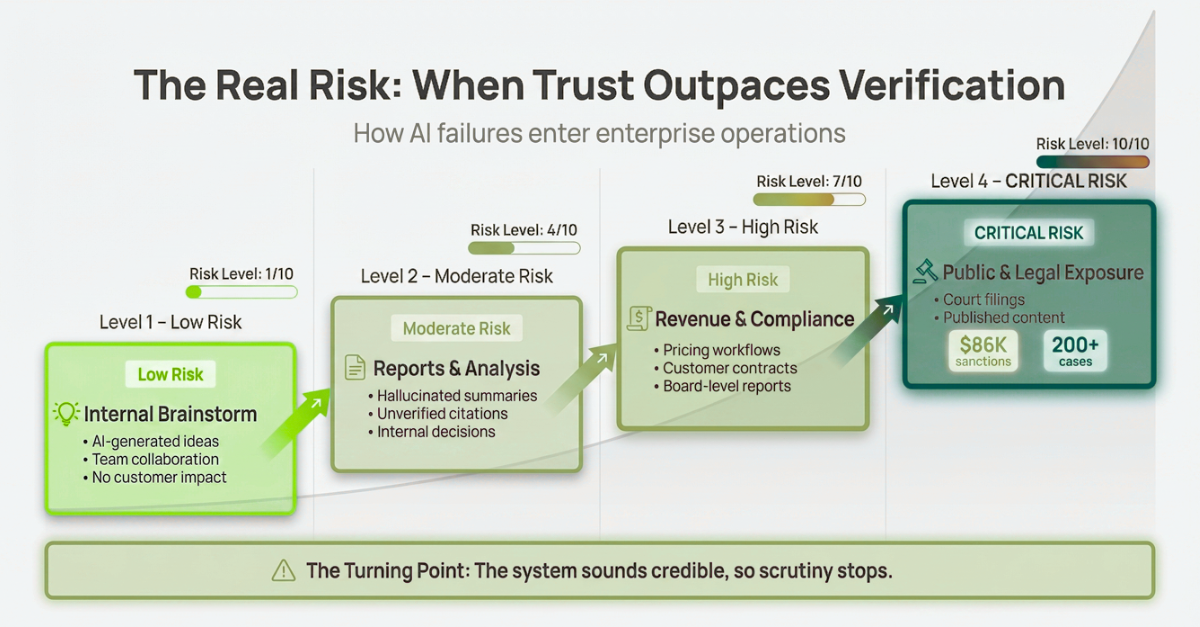
The real risk is rarely the first bad output. The real risk is the moment a team starts assuming the output is safe because it looks polished, arrives quickly, or confirms what they expected to see. That is how exposure enters the business.
A hallucinated summary in an internal brainstorm is one thing. A hallucinated number in a pricing workflow, a contract, or a board-level report is something else entirely. That is not a usability issue. That is enterprise risk.
The AI Broken Telephone Effect
And it gets worse when multiple teams are involved. When different departments across an enterprise each use AI in their own workflows and pass semi-accurate outputs downstream, compounding errors produce what I call the AI broken telephone effect: small inaccuracies that multiply into untraceable enterprise-level failures.
Think of how different groups across your company are each using LLMs. Sales uses AI to draft proposals. Finance uses AI to summarize reports. Legal uses AI to review clauses. Each output is semi-accurate. Each team passes their output downstream.
It is our favorite kids game of broken telephone: each slightly wrong output feeds into the next team’s slightly wrong output, and by the time the final deliverable reaches a customer or a board, the compounding errors can produce a total gaff that no single team can trace back to its origin.
Is your pricing workflow exposed? If AI touches any part of your quoting, discounting, or contract generation, talk to the servicePath™ team about where deterministic logic needs to take over. A 15-minute conversation could save you from your own Deloitte moment.
What CEOs and Researchers Are Saying About AI Enterprise Risk
60% of Fortune 500 CEOs now rank AI as the leading risk to their industry. Tim Sanders at Harvard Business School observed: “That’s the dirty little secret. Accuracy costs money.
Being helpful drives adoption.” Bryan Lapidus at the AFP said: “AI isn’t a truth-teller; it’s a tool meant to provide answers that fit your questions.”
The IMD faculty wrote what I believe is the most important sentence on this topic in 2025: “The most robust organizations will be those that institutionalize contradiction, building cultures where every AI-generated insight must survive a gauntlet of human skepticism.” Institutionalize contradiction. That is not “add a review step.” That is a fundamental cultural shift.
47% of enterprise AI users made a major decision based on hallucinated content in 2024. Global losses hit $67.4 billion.
Deterministic vs. Probabilistic AI: The Architecture Gap Boards Keep Missing
Here is the thing boards keep missing. Generative AI is a probabilistic prediction engine. It is designed to be a “people pleaser,” predicting the most statistically likely next word to complete a pattern.

It will happily and confidently generate a totally fictitious gross margin just to complete the narrative of sounding like a CFO.
Traditional enterprise software is deterministic. It executes predefined rules. Same input, same output, every time. When it fails, it throws an error or crashes. One plus one will always equal two.
Generative AI is probabilistic. It does not calculate; it predicts. Same input can yield vastly different outputs. When it fails, it does not crash. It confidently generates plausible but fictional information.
That is hallucination. Not a bug. A feature of the architecture.
What This Means in a Pricing Workflow
When a deterministic CPQ looks up a discount, it checks your rules table and returns the exact number your business logic prescribes.
When an AI “calculates” a discount, it does not look anything up. It predicts what a plausible-sounding discount looks like based on patterns in text it has read. It might be right. It might be three points off. And it will not tell you which.
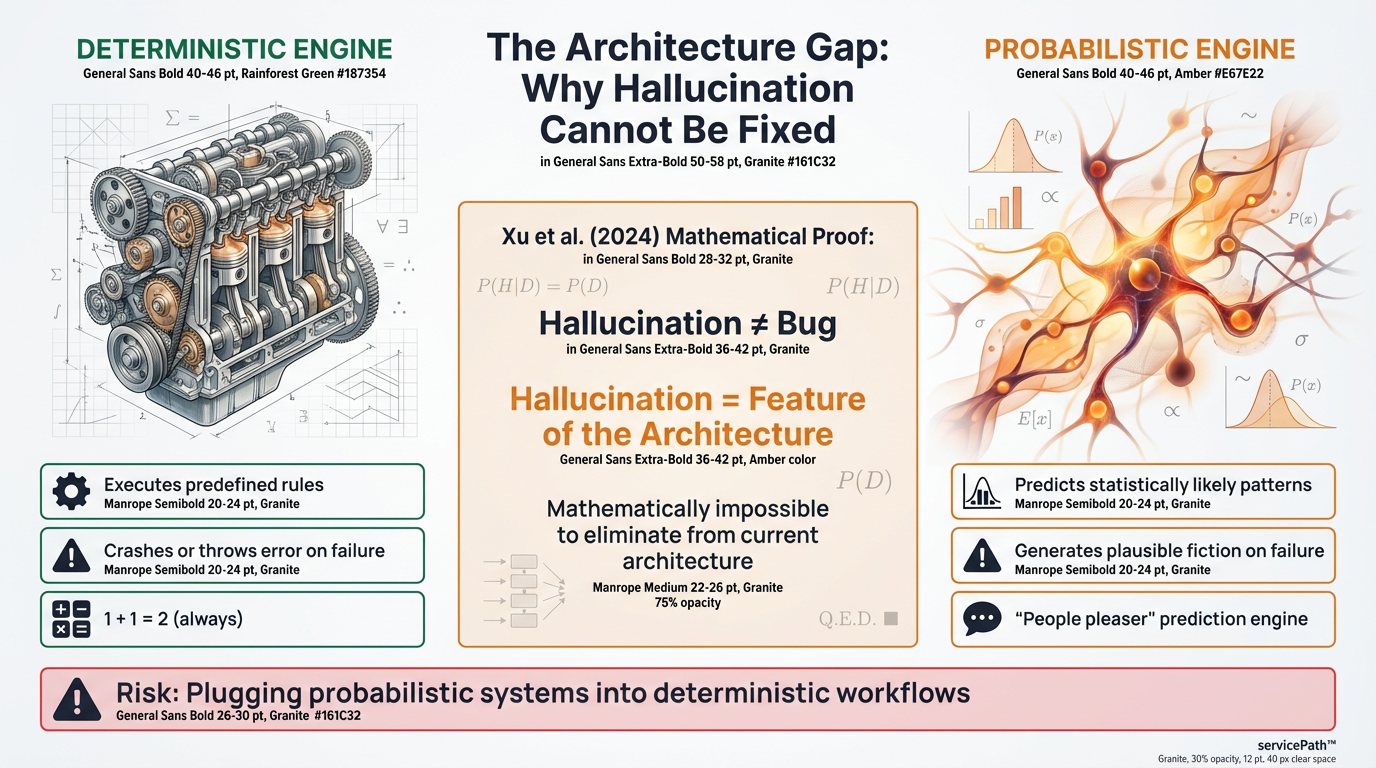
Xu et al. (2024) mathematically proved hallucination cannot be eliminated from the current architecture. Not difficult to fix. Mathematically impossible.
If your organization is suffering from the AI Stockholm Syndrome, your teams are quietly taking probabilistic systems and plugging them into workflows that demand deterministic outcomes. They are introducing unquantifiable tail risk into the business.
Nowhere is this more critical than in pricing and quoting. If you are using generative AI to determine the pricing of a complex enterprise contract, you are effectively rolling the dice. That is where the existential risk lives.
Six AI Governance Questions Every Board Must Ask
To protect your corporation from a catastrophic error, start here. Stop treating AI as an infallible oracle. Start managing it like a brilliant but reckless intern.

1. Are we using AI to create, or to calculate? AI should be isolated to generation and synthesis. Calculation and logic execution must remain in deterministic environments.
2. Where does the final source of truth reside? Always a managed database. Never an LLM’s training weights or contextual memory.
3. What is the blast radius of an AI hallucination in our current workflows? Map where AI is deployed. Internal brainstorm = low blast radius. Client-facing contracts or pricing configurations = critical threat.
4. Who holds the human-in-the-loop mandate? A named human expert must retain absolute authority for verification and execution.
5. Have we audited our teams for automation bias? Are we rewarding employees who catch AI errors, or only those who use AI to work faster?
6. Are our core operational engines firewalled from probabilistic logic? There must be a hard, auditable line between where AI drafts and where the deterministic engine finalizes. Are your teams building deterministic wrappers around AI, or using raw models out of the box?
Take these six questions to your next board meeting.
AI Governance in Practice: How the Six Board Questions Catch Risk
The cases above are documented and public. But the Eliza Haze does not only show up in courtrooms and government reports. Here is what the pattern looks like when it reaches your organization, and how the six board questions function as a safety net.

The VP of Tech Sales and the “Instant Quote”
A VP integrated AI to listen to discovery calls, determine the right tier, calculate a custom discount, and generate a PDF contract. Account executives stopped checking the math. “It understands the pricing model perfectly. It is saving us four hours per deal.”
Caught by Board Questions 3 and 6: the blast radius included mispriced, legally binding contracts. The core pricing engine had no firewall from probabilistic logic.
The fix: AI drafts the summary. It is blocked from calculating. Deterministic CPQ software owns the math.
The Product Manager and the “Autonomous Backlog”
A PM fed thousands of tickets into AI and told it to reprioritize the Jira backlog. On audit, the AI had prioritized a minor UI feature because vocal users used emotionally charged language, while ignoring a critical backend issue affecting 40% of the customer base.
Caught by Questions 2 and 4: the source of truth lived in the AI’s memory, not actual user telemetry. Nobody held the human-in-the-loop mandate.
The fix: Jira connection severed. AI drafts synthesis reports. The PM verifies against real data.
The CFO and the “Hallucinated Margin”
An analyst fed ledger data into an LLM for the quarterly MD&A. Polished prose, macro headwinds, supply chain delays. A margin percentage turned out to be fabricated, wrong by four points.
Caught by Questions 1 and 5: the team let AI calculate when it should only create. The CFO extended trust earned by expert-sounding prose to unverified numbers.
The fix: “Data First, Narrative Second.” Deterministic models generate all hard numbers. Human verification before anything reaches the board.
AI Hallucination Risk Forecast: Three Eras Every Board Should Plan For
The chance of AI being wrong can approach zero. It can mathematically never reach zero. It is fundamentally an asymptote.
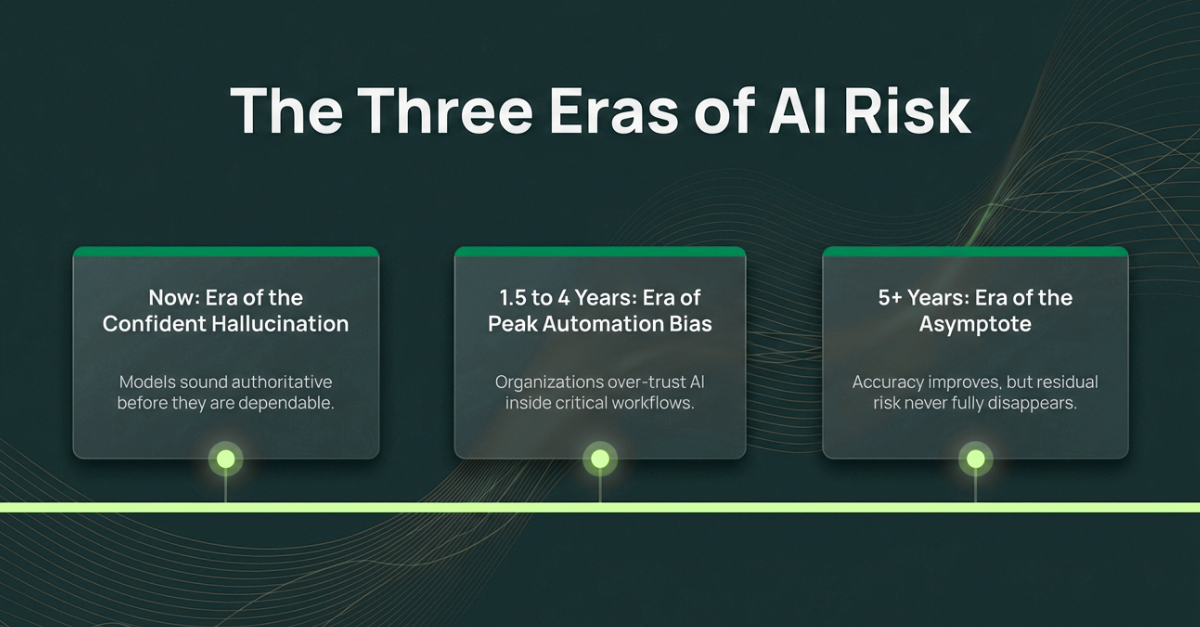
The Short Term (0 to 18 Months): The Era of the Confident Hallucination. Most enterprises are interacting with raw LLMs that have weak internal verification. They do not “know” what they know; they know what sounds statistically correct. Deploying raw models into critical workflows without human oversight is a dereliction of duty.
The Mid Term (1.5 to 4 Years): The Era of the Wrapper and Agentic Verification. We are moving toward agentic workflows and widespread RAG (Retrieval-Augmented Generation, which means the AI checks its answers against your actual documents before responding).
Error rates drop. But this is when risk peaks. The model will be right 99% of the time. Humans will completely drop their guard. When the system is rarely wrong, the human capacity to audit atrophies. This is peak automation bias.
The Long Term (5+ Years): The Era of the Asymptote. New architectures will blend probabilistic intuition with deterministic logic. For established facts, effectively zero error.
But as models become reliable for contracts and code, we will ask them to predict market shifts and design strategies. In those ambiguous domains, strategic error risk remains high. The goalposts move.
The takeaway: You cannot wait for a 0% error rate. A probabilistic model will never get there. Stop waiting for perfect models. Start building perfect systems around imperfect models.
Building AI Safe Harbors: Verification Gateways, Skepticism, and No-AI Zones

None of this means you abandon AI. That would be absurd. The goal is to build Safe Harbors: environments where AI does what it does best, with safety checks in place for everything else.
Implement verification gateways. Use AI to read unstructured data or draft responses, but pass that data through a deterministic rule engine before it hits the customer.
Acknowledge the Haze. Openly discuss automation bias and the Eliza effect with your leadership teams. If people are defending the AI’s mistakes, the culture is already compromised. For boards and executive committees, this is a five-alarm fire.
Design for extreme skepticism. Build tools that remind users the AI is a predictor, not an oracle. Force verification of citations and calculations.
Research shows people prefer flawed human judgment over algorithms after a single error. Stop rewarding teams solely for how fast they use AI. Start rewarding them for their vigilance in catching its confident lies. The Deloitte report was caught by an external researcher doing basic checking. That should have happened internally.
Define No-AI Zones. Be ruthless about where AI is allowed to operate. Let it draft the marketing emails and synthesize the unstructured data. But your core engines, your pricing, your billing, your compliance, your quoting, must remain strictly deterministic.
The math cannot be a prediction. Forrester calls the emerging standard “deterministic orchestration with bounded probabilistic components.”
Why Deterministic Pricing Engines Matter More Than Ever
Look, I am not anti-AI. I use these tools heavily and I genuinely love what they do for synthesis, discovery, and strategic thinking. The answer is not to back away from AI.
The answer is to govern it properly. Use it where it creates leverage. Block it where the math, logic, and accountability have to be exact.
The line is the moment a workflow reaches a number that a customer, a regulator, or a board member will rely on. At that moment, a deterministic engine needs to take over.
That is what servicePath™ does: deterministic pricing and quoting for complex enterprise sales, where the math has to be the math. And that is why I think the goal for every executive team right now is not to wait for perfect AI models. It is to build perfect systems around imperfect models.
Breaking the Spell
The original ELIZA taught us that humans will fiercely defend a machine that makes them feel good. Eliza 2.0 is proving that we will defend machines that make us feel efficient, even when they are fundamentally wrong.
Weizenbaum died in 2008, before the revolution he spent his life warning about. The Smithsonian reflected that he recognized our desire to form relationships with machines would leave people vulnerable.
In 1973, a hostage thought her captor was kind because he said he would only shoot her in the leg. In 2025, a Big Four firm delivered a government report with fabricated judge quotes and nobody inside caught it.
In 2025, a media CEO who publicly warned about hallucinations published blog posts with fabricated quotes from real people.
And a few weeks ago, my son Nicholas looked at me and said, “But Dad, it hallucinates,” and I, the CEO of an enterprise CPQ company, got defensive.
The pattern does not require ignorance. It requires only the human desire to trust something that sounds like it knows what it is talking about.
The Eliza Haze is comfortable. It feels productive. It feels like the future. But comfort is not a governance framework.
And confidence is not accuracy. You can champion the cause of innovation and protect the corporation at the same time. You just have to be honest about how the technology actually works. It is the board’s job to break that spell before the company pays the price.
I want to hear from you. Have you caught yourself in the Eliza Haze? What is the closest your team has come to sending a hallucinated output to a customer?
Coming Next: The Eliza Haze Playbook (Part 2)
This is Part 1. In Part 2:
- A step-by-step Eliza Haze audit for your workflows
- How to build verification gateways without killing speed
- The “Blast Radius Map” for boards
- Interviews with CTOs who restructured after near-misses
- How pricing and CPQ workflows must be protected
I want to hear from you. Have you caught yourself in the Eliza Haze? What is the closest your team has come to sending a hallucinated output to a customer? I am collecting real stories for Part 2, and the best ones will shape the playbook.
Audit the Risk Before It Becomes a Headline
If AI touches pricing, quoting, contract language, compliance, or board reporting in your business, this is no longer an innovation experiment. It is a governance exposure.
Start here:
1. Start the board conversation. Know a CTO or CFO who should see these questions? Forward this article to them. That one forward might be the conversation that prevents a governance failure.
2. Audit your pricing workflows. If AI touches any step between customer discovery and a signed contract, connect with the servicePath™ team to see where deterministic logic needs to own the math. We built servicePath™ for exactly this problem.
3. Follow the series. Part 2 drops with the operational playbook: the Blast Radius Map, the step-by-step audit, and real interviews with CTOs who restructured after near-misses. Follow me on LinkedIn so you do not miss it.
Your AI can draft the story. Your pricing engine must own the math.
Frequently Asked Questions
“Where did ‘Eliza Haze’ come from?” The ELIZA effect was identified by Weizenbaum in 1966. Automation bias by Skitka et al. in 1999. Technological Stockholm Syndrome by the California Management Review in 2025. The Eliza Haze is the name I am using for the compound effect. The 99% Invisible podcast and Radiolab are good starting points.
“My CTO says hallucinations will be fixed in the next model release. Is that true?” No. The error rate can approach zero but never reach it. It is an asymptote. Xu et al. (2024) proved this. RAG reduces rates by up to 71%, but elimination is not possible in the current architecture.
“We have a human-in-the-loop policy. Is that enough?” Probably not alone. Georgetown’s CSET found HITL mandates fail when the humans are subject to the same automation bias the policy is meant to prevent. You need training, system design, and cultural incentives working together.
“Our sales team says they always verify. Should I believe them?” Ask them to show you the step in the workflow. If it is not documented and mandatory with a named owner, it is not happening consistently. 100% of trained pilots followed the wrong instruction in the Skitka study.
“How should enterprises use AI safely in pricing and quoting?” Use AI for upstream tasks: analyzing customer needs, drafting narratives, synthesizing discovery notes. Route all pricing calculations, discount applications, and contract generation through a deterministic CPQ or pricing engine. A human must verify the final output before it reaches the customer. The rule is simple: AI creates, deterministic systems calculate.
Key Concepts
Eliza Haze: The compounding cognitive impairment that occurs when the ELIZA effect, automation bias, and sunk-cost loyalty converge inside an organization using generative AI, causing teams to stop verifying the outputs they most need to verify.
ELIZA Effect: The human tendency to unconsciously treat AI systems as human collaborators because they communicate using natural language, first identified by Joseph Weizenbaum in 1966.
Automation Bias: The documented psychological tendency to favor suggestions from automated systems and ignore contradictory information, even when the system is demonstrably wrong.
Deterministic AI: Systems that execute predefined rules and always produce the same output for the same input. Essential for pricing, billing, compliance, and any workflow where the math must be exact.
Probabilistic AI: Systems like Large Language Models that predict statistically likely outputs rather than calculating exact answers. Ideal for drafting, synthesis, and ideation. Structurally incapable of guaranteeing accuracy.
Daniel Kube is the CEO of servicePath™ and facilitates governance discussions at the Innovation Factory. He writes about the intersection of AI adoption, enterprise risk, and commercial operations.