
Enterprise AI Implementation Strategy: Turn 95% Failure Rate Into Success
A comprehensive guide to enterprise AI implementation strategy that turns failure into strategic advantage through disciplined learning and measured risk-taking

Recent MIT research reveals a stark reality that should make every C-suite executive pause: roughly 95% of enterprise generative AI pilots aren’t delivering measurable business value. Only about 5% convert to rapid revenue impact; the rest stall on the P&L. Meanwhile, S&P Global Market Intelligence shows companies are getting more disciplined—42% are now scrapping most AI initiatives (up from 17% last year), with enterprises abandoning 46% of POCs before production.
But here’s the counterintuitive truth that separates winning organizations from the pack: this isn’t doom—it’s exactly how breakthrough technologies should be adopted by responsible leaders. The most effective enterprise AI implementation strategy doesn’t avoid failure—it harnesses controlled failures as training wheels for sustainable competitive advantage.
The Training Wheels Analogy: How We Actually Learn

Think back to when you first learned to ride a bike. Before you ever climbed on, that bike looked terrifying—a guaranteed crash waiting to happen.
Then you sat on it. “Okay, this isn’t so bad.”
You pushed off with confidence… wobbled… lost balance… and wiped out spectacularly.
So you did what every smart person does: you bolted on training wheels. You built balance gradually. You learned the feel of momentum, steering, and stopping. And one day, without even noticing, those training wheels weren’t touching the ground anymore.
Enterprise AI implementation strategy works exactly the same way. Early “failures” aren’t failures at all—they’re training wheels. And the smartest leaders use them on purpose.
The MIT study’s methodology has faced significant scrutiny from industry experts who point out its narrow definition of success focusing solely on rapid revenue acceleration within six months, potentially overlooking efficiency gains and cost reductions. However, the core insight remains valid: most organizations struggle to move beyond experimentation to production-scale value creation.
At servicePath™, we’ve seen this pattern repeatedly—companies that embrace controlled learning through AI training wheels consistently outperform those that either avoid AI entirely or jump straight to full automation. Our enterprise AI implementation strategy focuses on building sustainable competitive advantage through measured risk-taking.
For Boards and Senior Leaders: Why This Creates Shareholder Value
The “95% failure” narrative misses the strategic point entirely. Here’s why disciplined enterprise AI implementation strategy—including planned “failures”—creates shareholder value:

Designed Learning, Not Chaos
Smart leaders treat pilots as governed experiments with clear guardrails and success criteria, not moonshot gambles. Each failure generates valuable data that improves policies, data quality, and process design. As Alexander Sukharevsky, Senior Partner at McKinsey, notes: “The more we see organizations using AI, the more we recognize that it takes a top-down process to really move the needle. Effective AI implementation starts with a fully committed C-suite and, ideally, an engaged board.”
Portfolio Logic for Maximum Learning
Many small bets with tight scopes enable fast kill-or-scale decisions. This maximizes learning per dollar invested while minimizing blast radius of any single failure. Organizations following this approach report 3.7x to 10.3x returns on generative AI investments. The key is treating each pilot as a bounded experiment with clear success criteria and promotion gates.
Leading Indicators Over Lagging Metrics
Track time-to-safe-auto-apply and edit-distance-to-final as predictive metrics, not just lagging ROI measures. These show velocity of organizational learning and readiness for scale. McKinsey research indicates that CEO oversight of AI governance correlates with highest EBIT impact, particularly in larger organizations.
Transparent Risk Management for Stakeholder Confidence
Publicly define green/yellow/red risk bands (what’s auto-apply vs. co-pilot vs. block) so governance decisions are visible and auditable to stakeholders. 80% of organizations now have dedicated AI risk functions, with 55% implementing fully centralized compliance models that provide board-level visibility into AI governance.
Trust Infrastructure That Reduces Enterprise Risk
Citation requirements (“Why panels”), watermarked drafts, and strict access controls systematically reduce reputational, legal, and data-exposure risks. Organizations are actively addressing AI implementation challenges, with 12% increase in inaccuracy risk management and 18% increase in cybersecurity risk focus year-over-year.
The Goldilocks Principle for Competitive Advantage
If you’re not experiencing a measured rate of safe, instrumented “micro-failures,” you’re probably not pushing hard enough to capture competitive advantage. But if failures aren’t generating systematic improvements in data quality, process design, and governance frameworks, you’re not learning efficiently. The sweet spot is controlled experimentation with rapid feedback loops.
As Dan Priest, Chief AI Officer at PwC, emphasizes: “Top performing companies will move from chasing AI use cases to using AI to fulfill business strategy.”
Board Messaging: Positive Failure as Stakeholder Value
For board communications and stakeholder updates: Frame AI pilots as a strategic learning portfolio where controlled failures accelerate competitive positioning. Emphasize that organizations avoiding all AI risk are ceding market position to competitors who are learning faster. The goal isn’t zero failures—it’s maximum learning velocity within defined risk parameters.
Key board talking points:
- “We’re building institutional AI capabilities through disciplined experimentation”
- “Our failure rate indicates we’re pushing boundaries while maintaining governance”
- “Each pilot generates data that improves our next implementation”
- “We’re investing in competitive advantage, not just technology”
The Six Stages: From “Won’t Sit” to “Full Ride”
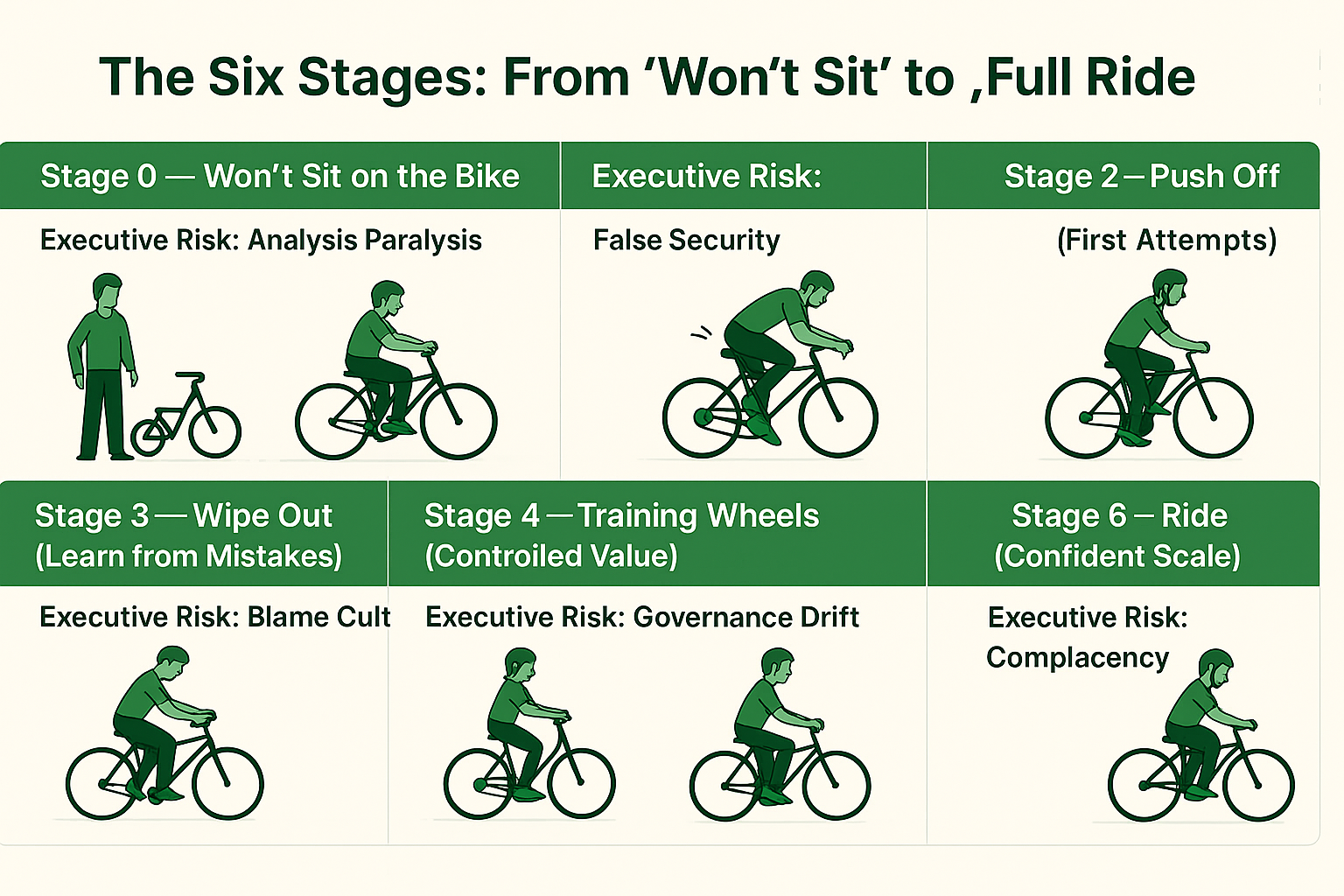
Successful enterprise AI implementation strategy follows a predictable progression. Our AI governance framework ensures each stage builds systematically on the previous one, minimizing risk while maximizing learning velocity.
Stage 0 — Won’t Sit on the Bike (Executive Risk: Analysis Paralysis)
You’re paralyzed by abstract risk. Everything feels like a potential catastrophe.
- Actions: Pick 2–3 high-value, low-blast-radius use cases. Define red lines before granting access.
- Executive risks to monitor: Vague goals + broad access = data leakage and shadow IT proliferation. McKinsey research shows that 47% of organizations experienced negative consequences from generative AI use, including inaccuracies, IP infringement, and privacy breaches.
- Board governance: Establish clear use case selection criteria and risk tolerance thresholds before any AI deployment.
Stage 1 — Sit (Getting Comfortable) (Executive Risk: False Security)
Create safe space to explore without breaking anything.
- Actions: Safe sandboxes, masked data, prompt libraries, grounding to internal sources only.
- Executive risks to monitor: Hallucinations from ungrounded prompts; prompt injection attacks; stale policies. Organizations report that only 27% review all generative AI outputs before use, creating significant risk exposure.
- Board governance: Require regular security audits and policy updates during sandbox phase.
Stage 2 — Push Off (First Attempts) (Executive Risk: Premature Scaling)
Launch pilots with heavy human oversight and logging.
- Actions: Human-in-the-loop everything; capture accept/edit/reject decisions with reason codes.
- Executive risks to monitor: “Automation bias” (people blindly accepting bad AI suggestions); missing audit trails. CIO research indicates that change management is often harder than the technology solution itself.
- Board governance: Establish clear metrics for human oversight effectiveness and decision quality.
Stage 3 — Wipe Out (Learn from Mistakes) (Executive Risk: Blame Culture)
Hit your first real errors—and treat them as valuable telemetry.
- Actions: Tighten scope, improve retrieval, fix data quality issues.
- Executive risks to monitor: Blaming “the model” instead of fixing underlying data and policy problems. Data quality issues cost the U.S. economy $3.1 trillion annually, making this stage critical for long-term success.
- Board governance: Frame errors as learning investments and require systematic root cause analysis.
Stage 4 — Training Wheels (Controlled Value) (Executive Risk: Governance Drift)
Add structure that lets AI help while keeping guardrails firm.
- Actions: Narrow task focus; add “Why” panels with citations; keep everything as suggestions only.
- Executive risks to monitor: Model or template drift; PII creeping into prompts; losing explainability. Gartner identifies a critical 3-6 month window for CIOs to define AI strategies before falling behind peers.
- Board governance: Implement regular governance reviews and maintain strict explainability requirements.
Stage 5 — Balance (Selective Autonomy) (Executive Risk: Uncontrolled Expansion)
Allow limited auto-execution within tiny, well-defined risk bands.
- Actions: Auto-apply only inside small risk bands; everything else stays suggestions.
- Executive risks to monitor: Expanding bands without statistical evidence; skipping reviews during volume spikes. McKinsey research shows that only 19% track well-defined KPIs for generative AI solutions.
- Board governance: Require data-driven justification for any expansion of autonomous capabilities.
Stage 6 — Ride (Confident Scale) (Executive Risk: Complacency)
Increase autonomy systematically based on proven safety and value metrics.
- Actions: Widen bands based on evidence; maintain vigilance for new edge cases.
- Executive risks to monitor: New markets, currencies, or product mixes introducing unforeseen failure modes. High-maturity organizations keep 45% of AI projects operational for at least 3 years, compared to much lower rates for less mature organizations.
- Board governance: Establish continuous monitoring systems for new risk vectors and market changes.
Four High-Value Applications Perfect for Training Wheels
These applications represent the sweet spot for enterprise AI implementation strategy—high business impact with manageable risk when proper training wheels are applied. Our AI-powered CPQ platform demonstrates these principles in action.
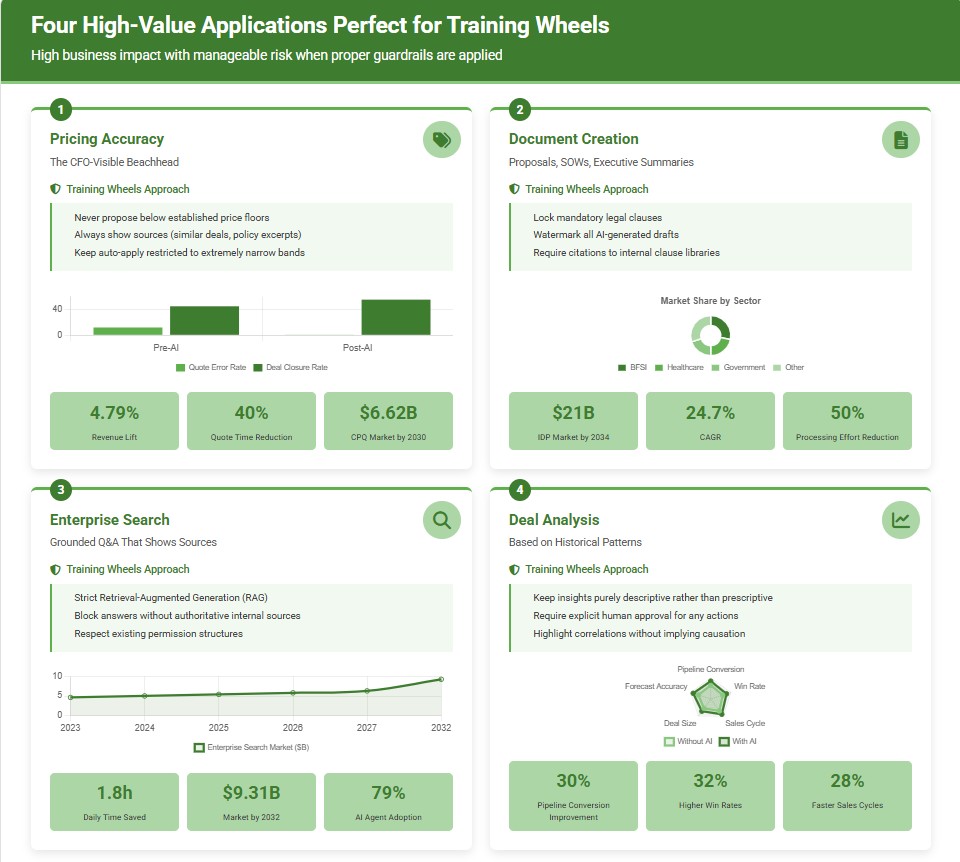
1) Pricing Accuracy—The CFO-Visible Beachhead
- What AI does: Suggests price ranges and discount levels based on similar historical deals, segment rules, and current guard bands. Flags margin risks and pricing inconsistencies before they hit the quote.
- Training wheels approach: Never propose below established price floors; always show sources (“similar deals,” “policy excerpt,” “segment guideline”); keep auto-apply restricted to extremely narrow bands initially.
- Executive governance considerations: Pricing AI requires board-level oversight due to competitive implications and margin impact. Establish clear escalation paths for pricing decisions outside normal parameters.
- Dangers to actively monitor: Sensitive pricing data leakage, algorithmic bias toward historically over-discounted customer segments, complex bundle pricing calculations that seem logical but are mathematically incorrect.
- Real-world impact: Organizations implementing AI-driven pricing intelligence report revenue lifts of up to 4.79% and quote turnaround time reductions of up to 40%. The CPQ software market is projected to reach $6.62 billion by 2030, with AI integration as a key growth catalyst.
For example, manufacturing firms report quote error reductions of up to 98% post-AI implementation, while deal closure rates increase by an average of 23% with AI-enhanced quote generation. Cloud-based CPQ deployments dominate with 58.8% market share, growing at a 19.2% CAGR as AI features prove more readily scalable in cloud environments.
2) Document Creation—Proposals, SOWs, Executive Summaries
- What AI does: Drafts from pre-approved templates, summarizes contract redlines, generates executive summaries, creates proposal alternatives and pricing scenarios.
- Training wheels approach: Lock mandatory legal clauses; watermark all AI-generated drafts; require citations to internal clause libraries; never auto-send external documents.
- Executive governance considerations: Document AI affects legal risk and client relationships. Require legal review of all template changes and maintain strict version control.
- Dangers to actively monitor: Hallucinated contract terms that don’t exist in your templates, outdated language that conflicts with current policies, tone or compliance mismatches that could harm client relationships.
- Market validation: The Intelligent Document Processing market is projected to reach $21 billion by 2034, representing a robust 24.7% CAGR. This explosive growth is driven by global digital transformation investments exceeding $1.85 trillion in 2023 and AI/ML advancements enabling automation of regulatory compliance workflows.
Early adopters report 50% reduction in manual document processing effort and error reductions exceeding 52%. Large language models and AI agents are enhancing document understanding capabilities, with solutions now handling diverse document types including images, videos, and handwritten text.
The BFSI sector leads adoption with 26-30% market share, followed by healthcare and government sectors where IDP automates records management and compliance workflows. North America holds the largest market share at 40%, while Asia-Pacific represents the fastest-growing region due to digitalization initiatives.
3) Enterprise Search—Grounded Q&A That Shows Sources
- What AI does: Answers questions like “What’s our latest pricing policy for EMEA?” or “Which proposal template should I use for government clients?” by retrieving and citing internal knowledge sources.
- Training wheels approach: Implement strict Retrieval-Augmented Generation (RAG) with access controls; block any answers that can’t cite authoritative internal sources; respect existing permission structures.
- Executive governance considerations: Enterprise search affects information security and competitive intelligence. Establish clear data classification and access control policies.
- Dangers to actively monitor: Answers without proper source grounding, cross-tenant data bleed between different business units, over-broad indexing that exposes confidential documents.
- Productivity gains: AI search assistants reduce employee search time by up to 1.8 hours per day, with 78% of organizations now using AI in at least one business function. The enterprise search market was valued at $4.61 billion in 2023 and is projected to reach $9.31 billion by 2032 with a CAGR of 8.2%.
AI-powered search tools are reducing traditional search engine click-through rates by up to 34.5% as users prefer direct AI-generated answers. The rise of agentic AI—systems that autonomously perform tasks—is particularly significant for knowledge discovery, with 79% of organizations having adopted AI agents to some extent and 96% planning to expand their use.
Retrieval-Augmented Generation (RAG) is critical for enterprise applications as it grounds AI responses in verifiable internal documents and data sources, making it ideal for internal document analysis and decision-making while reducing AI hallucinations.
4) Deal Analysis Based on Historical Patterns
- What AI does: Surfaces look-alike successful deals, predicts time-to-close factors, flags anomalies like unusual margin drift or non-standard contract terms that historically correlate with problems.
- Training wheels approach: Keep insights purely descriptive rather than prescriptive; require explicit human approval before taking any actions based on AI recommendations.
- Executive governance considerations: Deal analysis affects revenue forecasting and strategic planning. Ensure AI insights complement rather than replace human judgment in deal strategy.
- Dangers to actively monitor: Confusing correlation with causation in deal patterns, reinforcing historical biases in sales processes, ignoring important seasonality or currency effects that change deal dynamics.
- Revenue intelligence impact: Companies using advanced revenue intelligence tools are projected to outperform competitors by up to 30% in pipeline conversion rates. Organizations report 32% higher win rates and 28% faster sales cycles.
The AI in sales market is forecasted to reach $4.5 billion by 2025, with 90% of companies expected to adopt AI for sales analytics. Market adoption is accelerating rapidly, with a 47% year-over-year increase in revenue intelligence platform adoption.
AI-powered forecasting models are reducing missed revenue forecasts by 83%, while predictive deal scoring using CRM and behavioral data generates 25% higher forecast accuracy. Organizations implementing these solutions show revenue growth of 83% for AI-using teams vs. 66% for non-AI teams.
Evidence Over Enthusiasm: Concrete Promotion Gates
Therefore, track these metrics from day one and only advance when the data definitively supports it:
- First-draft cycle time (quotes/proposals/emails/search answers): Target 30-60% reduction by end of training-wheels phase
- Edit distance (AI draft → final version): Less than 20% changes on top patterns before allowing any auto-apply
- Suggestion acceptance rate: Greater than 60% with zero policy breaches for 3 consecutive weeks
- Explainability coverage: “Why” explanation shown on ≥95% of AI suggestions
- AI-caused exception rate: Absolute zero during pilot phases; less than 0.5% once limited auto-apply bands open
- Data exposure incidents: Zero tolerance—actively scan prompt logs for PII, API keys, or other sensitive data
Sample promotion gate: Only advance from suggestions-only to limited auto-apply when acceptance rate >60%, edit distance <20%, and zero policy breaches for 3 straight weeks.
Executive governance for promotion gates: Require C-suite sign-off for any advancement beyond Stage 4 (Training Wheels). Each promotion gate should include board-level risk assessment and competitive impact analysis.
Moreover, Organizations tracking well-defined KPIs for AI solutions report significantly higher business impact, yet only 19% currently do so effectively. Forecast accuracy targets of 90-95% are considered excellent, with typical sales cycle reductions of 10-25% achievable through systematic implementation.
The Training Wheels Phase: Why It Takes Time (And Should)
Additionally, early AI value isn’t blocked by models; it’s blocked by trust, governance, and data shape. The training-wheels phase exists to build those three muscles without stalling delivery. Think of it as four overlapping curves you need to raise together:
- Capability (what the AI can do)
- Safety (what it must never do)
- Evidence (proof it’s helping)
- Adoption (people actually using it)
Sub-stages of Training Wheels
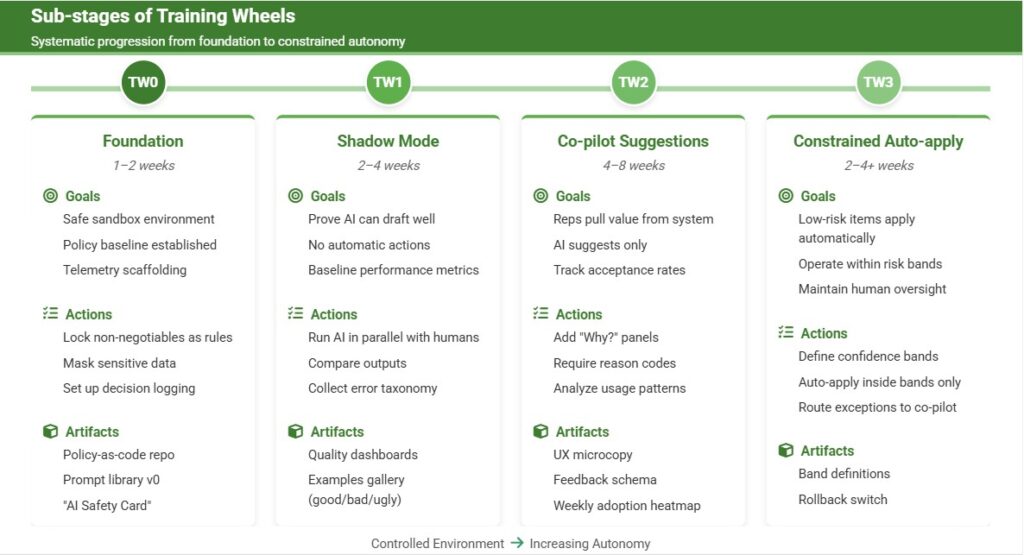
TW0 — Foundation (1–2 weeks)
- Goals: safe sandbox, policy baseline, telemetry scaffolding
- Actions: Lock non-negotiables as deterministic rules, mask sensitive data, set up decision logging
- Artifacts: Policy-as-code repo, prompt library v0, “AI Safety Card”
TW1 — Shadow Mode (2–4 weeks)
- Goals: prove the AI can draft well while doing nothing automatically
- Actions: Run AI in parallel, compare deltas vs. human outputs, collect error taxonomy
- Artifacts: Quality dashboards, examples gallery (good/bad/ugly)
TW2 — Co-pilot Suggestions (4–8 weeks)
- Goals: reps pull value; AI still suggests only
- Actions: Expose suggestions with “Why?” panels, require reason codes for accept/edit/reject
- Artifacts: UX microcopy, feedback schema, weekly adoption heatmap
TW3 — Constrained Auto-apply (2–4+ weeks)
- Goals: very low-risk items apply automatically within bands
- Actions: Define confidence bands, auto-apply only inside bands, route everything else to co-pilot
- Artifacts: Band definitions, rollback switch, exception queue with SLA
Harvard Business Review warns against the “AI experimentation trap”, where leaders repeat digital transformation mistakes by funding scattered pilots that lack strategic alignment. The structured training wheels approach avoids this by maintaining clear progression gates and business alignment throughout.
Phased Training Wheels Playbook
Safe Harbor: The durations below are indicative ranges, not guarantees. Actual timelines depend on factors including use-case complexity, data quality and availability, policy clarity and breadth, integration surface area and technical debt, volume and variance of patterns, regulatory constraints, multi-geo/currency/partner complexity, security/privacy posture and approvals, change-management maturity, decision latency for approvals, staffing and SME availability, model/infra readiness, seasonality, and governance cadence.
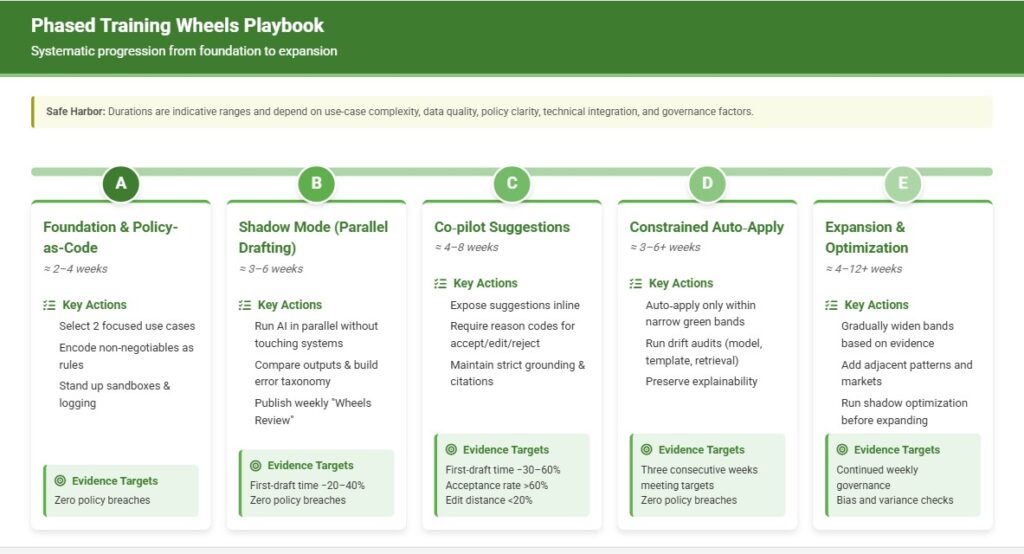
Phase A — Foundation & Policy-as-Code (≈ 2–4 weeks)
- Select 2 focused use cases (e.g., pricing suggestions and document drafting)
- Encode non-negotiables as deterministic rules (price floors, approvals, mandatory clauses)
- Stand up sandboxes, masked data, logging, and “Why” panels (citations required)
- Instrument decision logging (accept/edit/reject + reason codes)
Phase B — Shadow Mode (Parallel Drafting) (≈ 3–6 weeks)
- Run AI in parallel without touching source-of-truth systems
- Compare deltas vs. human outputs; build error taxonomy and patch prompts/templates
- Publish a weekly “Wheels Review” with examples (good/bad) and band tweaks
- Evidence targets: first-draft time −20–40%; zero policy breaches
Phase C — Co‑pilot Suggestions (Human-in-the-Loop) (≈ 4–8 weeks)
- Expose suggestions inline; require reason codes for accept/edit/reject
- Maintain strict grounding and source citations; block uncited answers
- Evidence targets: first-draft time −30–60%; acceptance rate >60%; edit distance <20%
Phase D — Constrained Auto‑Apply (Green Band Only) (≈ 3–6+ weeks)
- Auto‑apply only within narrow, pre‑agreed green bands; keep everything else as suggestions
- Run drift audits (model, template, retrieval); preserve explainability
- Promotion gates: three consecutive weeks meeting targets with zero policy breaches
Phase E — Expansion & Optimization (Broaden Bands, Add Use Cases) (≈ 4–12+ weeks)
- Gradually widen bands based on evidence; add adjacent patterns and markets
- Introduce optimization in shadow (e.g., price optimization) before expanding auto‑apply
- Continue weekly governance; refresh historicals; run bias and variance checks
Mid‑market firms often scale faster (~90 days to first production) than large enterprises (often 9+ months). Use the ranges above to calibrate expectations; the right pace is the one your evidence supports.
Lightweight Governance Rhythm That Actually Works
Daily: Review top 10 misfires; patch prompts, templates, and retrieval filters based on real user feedback.
Weekly “Wheels Review”: 30-minute session covering key metrics, three real examples (good and bad), risk band adjustments, and field communications.
Monthly: Audit model versions and templates; refresh historical data; run bias detection checks; assess competitive positioning.
Executive Governance Rhythm:
- Quarterly Board Updates: Present learning velocity metrics, competitive positioning analysis, and strategic roadmap adjustments
- Monthly C-Suite Reviews: Assess promotion gate readiness, resource allocation, and cross-functional alignment
- Weekly Executive Dashboards: Track key safety and value metrics with exception reporting
RACI clarity: Operations owns rollout and metrics; Security owns data controls; Legal/Compliance owns red-line definitions; Enablement owns training and user adoption.
McKinsey identifies 12 adoption and scaling practices that correlate with success, including establishing dedicated teams, regular internal communications, senior leader engagement, role-based training, and effective embedding into business processes. Organizations following these practices report significantly higher EBIT impact from AI investments.
Common Anti-Patterns That Kill Progress
- Big-bang autonomy (“We’ve tested for two weeks—we’re ready to ride!”)
- Ungrounded generation (AI answers without showing sources)
- Unlogged suggestions (no systematic capture of what works and what doesn’t)
- PDF policies (governance stuck in documents instead of executable rules)
- Anecdotal expansion (widening risk bands based on success stories rather than statistical evidence)
CIO research emphasizes that change management is often harder than the technology solution itself, with Evette Pastoriza Clift, Global CIO at Mayer Brown, noting: “You can work very hard to put something fantastic in place. But if you haven’t gotten the willingness of people to make the change… you haven’t moved the dial.”
Risk Mitigation Throughout the Journey

Technical Risks
- Accuracy and reliability: Implement human-in-the-loop validation with clear escalation paths
- Security vulnerabilities: Establish comprehensive AI security governance with regular penetration testing. Brian Greenberg, CIO at RHR International, warns: “The cybersecurity risk exposures are huge, and they’re increasing tremendously with AI.”
- Integration failures: Design for interoperability and standardization from day one
Organizational Risks
- Change resistance: Invest in training and change management; 44% of workers face core skill disruption according to the World Economic Forum’s Future of Jobs Report 2025
- Skills gaps: Develop comprehensive reskilling programs; 23% of jobs will change significantly within five years
- Cultural barriers: Foster trust through transparency and education
Business Risks
- Unclear ROI: Establish multidimensional measurement frameworks beyond just revenue impact
- Regulatory compliance: Build governance frameworks for evolving regulations like the EU AI Act
- Competitive disadvantage: Act within critical 3-6 month strategy window identified by Gartner
Workforce Transformation and New Role Creation
The AI revolution is creating significant workforce impacts across all enterprise functions:
New Role Creation:
- AI compliance specialists (13% of new hiring)
- AI ethics specialists (6% of new hiring)
- Continued high demand for AI data scientists (50% report shortages)
- Prompt engineers (+135.8% year-over-year growth)
- AI content creators (+134.5% growth)
Reskilling Requirements:
Organizations report that only 44% reskilled up to 5% of workforce due to AI in the past year, while 38% expect minimal workforce changes from AI in the next 3 years. However, 70% of scaling AI efforts focus on people and processes rather than technology alone.
Shadow AI Economy:
90% of employees use personal AI tools vs. 40% with enterprise subscriptions, highlighting the need for formal AI strategies that embrace rather than restrict employee AI usage through proper governance frameworks.
The servicePath™ Approach: Deterministic Rails + Probabilistic Intelligence
At servicePath™, we’ve built our AI-powered CPQ platform around this exact training wheels philosophy. Our hybrid approach marries:
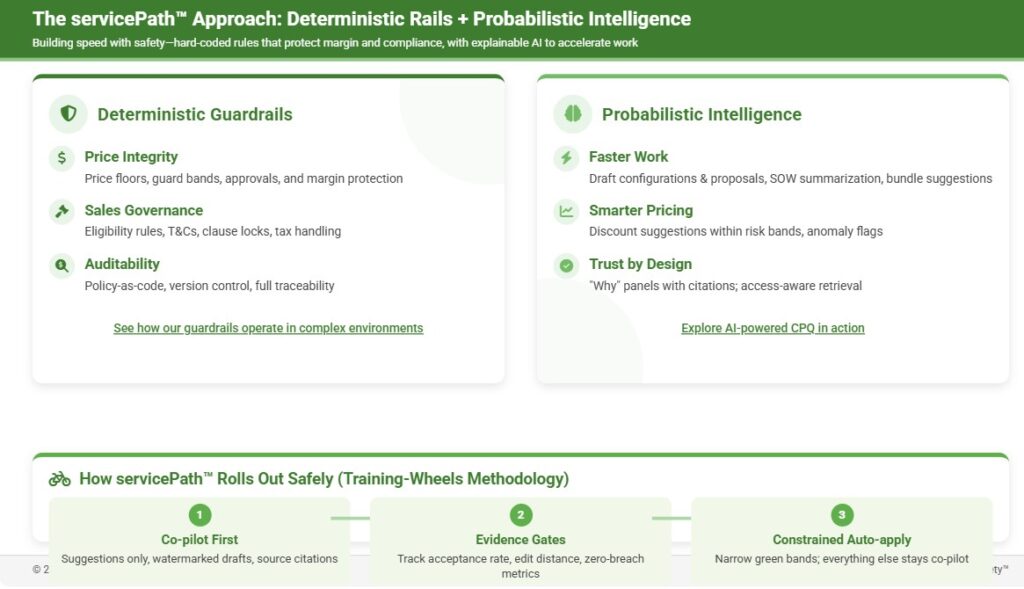
- Deterministic guardrails (the hard rules you must never break): product eligibility, price floors, approvals, T&Cs, tax calculations, compliance requirements.
- Probabilistic intelligence (the smart helpers that make people faster): draft configurations, summarize SOWs, suggest discounts, flag risks, recommend bundles, analyze deal patterns.
Consequently, start with co-pilot, ship small wins, measure impact, then dial up autonomy within defined risk bands. Guardrails keep you safe. Models make you fast. Together, they make AI actually ship.
Our approach aligns with digital transformation best practices and addresses the core challenges identified in enterprise AI implementation strategy.
Our approach aligns with industry best practices identified by PROS research, including integrated data systems, hybrid selling models, simplified product configurations, automated quote approvals, and AI-powered pricing intelligence. We’ve seen customers achieve 75% faster new product launches and 60%+ dealer portal order submission rates.
The servicePath™ Approach: Deterministic Rails + Probabilistic Intelligence

What makes servicePath™ different? We build CPQ for enterprises selling complex, ever-changing solutions. Our platform hard-codes the rules that protect margin and compliance, then layers explainable AI to accelerate configuration, pricing, and proposal work—so you get speed with safety.
Deterministic guardrails (non-negotiables)
-
Price integrity: price floors, guard bands, approvals
-
Sales governance: eligibility rules, T&Cs, clause locks, tax handling
-
Auditability: policy-as-code, version control, full traceability
See how our guardrails operate in complex environments:
https://servicepath.co/salesforce-cpq-alternative/?utm_source=blog&utm_medium=cta&utm_campaign=enterprise-ai-training-wheels&utm_content=sfcpq-alternative
Probabilistic intelligence (assistive AI that ships)
-
Faster work: draft configurations & proposals, SOW summarization, bundle suggestions
-
Smarter pricing: discount suggestions within risk bands, anomaly flags
-
Trust by design: “Why” panels with citations; access-aware retrieval
Explore AI-powered CPQ in action:
https://servicepath.co/?utm_source=blog&utm_medium=cta&utm_campaign=enterprise-ai-training-wheels&utm_content=platform-overview
How servicePath™ rolls out safely (training-wheels methodology)
-
Co-pilot first: suggestions only, watermarked drafts, source citations
-
Evidence gates: track acceptance rate, edit distance, and zero-breach metrics
-
Constrained auto-apply: narrow green bands; everything else stays co-pilot
Book a 90-day “AI Training Wheels” strategy session
Advanced Implementation Strategies for Enterprise Scale
Multi-Cloud and Hybrid Deployment Considerations
As organizations scale beyond initial pilots, cloud-native architecture becomes critical, with cloud-based deployments favored due to scalability and cost-efficiency. The cloud segment is expected to exceed $15 billion by 2034, supported by hybrid and multi-cloud adoption strategies.
Our CPQ platform integrations demonstrate how enterprise AI implementation strategy must account for complex system architectures and data flows across multiple environments.
Key architectural decisions:
- Data residency and sovereignty: Ensure compliance with regional regulations while maintaining performance
- Integration complexity: Legacy CRM and ERP system compatibility remains a primary challenge
- Real-time synchronization: Critical for revenue intelligence and pricing applications
- Disaster recovery: AI systems require specialized backup and recovery procedures
Industry-Specific Implementation Patterns
- Financial Services:
Financial services firms show higher likelihood of workforce reduction expectations from AI, with many building proprietary AI systems despite lower success rates for internal builds. Regulatory complexity creates additional implementation barriers, requiring specialized compliance frameworks. - Manufacturing:
AI-powered cybersecurity is becoming critical for connected devices and industrial control systems. Manufacturing faces shortage of skilled talent and training challenges as major hurdles, along with energy consumption considerations for AI deployments. - Professional Services:
Professional services firms are much more likely to review all AI outputs before use, focusing on regulatory monitoring and transaction analysis applications. Change management is particularly challenging due to professional skepticism.
Advanced Analytics and Performance Optimization
- Conversation Intelligence with NLP:
Revenue intelligence platforms are analyzing calls for sentiment and objection patterns, with 76% of B2B marketers reporting improved ROI from real-time buyer intent signals. - Dynamic Territory Management:
Advanced platforms are updating territories based on real-time buying signals, with embedded revenue intelligence providing alerts directly in Slack/Zoom workflows. - Generative AI for Sales Content:
79% of teams report execution benefits from AI-generated proposals, with autonomous sales process management platforms handling lead qualification without human intervention.
Frequently Asked Questions
Strategy and Planning
Q: How do I convince my board that a 95% failure rate is actually good news?
A: Frame it as designed learning with measurable gates. Show them the portfolio approach: many small, bounded experiments with clear kill/scale criteria generate more learning per dollar than big-bang deployments. The 5% that succeed often deliver 3.7x to 10.3x returns, making the portfolio math work. Emphasize that if you’re not experiencing controlled micro-failures, you’re probably not pushing hard enough to capture competitive advantage.
Q: What’s the difference between training wheels and just being overly cautious?
A: Training wheels have promotion gates based on evidence, not fear. Overly cautious organizations never advance beyond Stage 1. Training wheels organizations systematically expand autonomy when data proves safety and value. The key is having clear metrics and timelines for advancement, not indefinite human oversight. High-maturity organizations keep 45% of AI projects operational for at least 3 years, compared to much lower rates for less mature organizations.
Q: How long should the training wheels phase last?
A: Typically 90-180 days for most enterprise applications, but it varies by use case complexity and organizational readiness. Simple document generation might graduate in 60 days, while complex pricing optimization could take 6+ months. The key is evidence-based promotion gates, not arbitrary timelines. Mid-market firms scale AI faster (90 days) than large enterprises (9+ months).
Implementation and Risk Management
Q: How do I prevent “shadow AI” from undermining our formal AI strategy?
A: Embrace it strategically. 90% of employees use personal AI tools vs. 40% with enterprise subscriptions, so survey employees about their current AI tool usage, identify the highest-value applications, and bring them into your formal program with proper governance. Often, shadow AI reveals the real pain points your formal strategy should address. Make your official tools more useful than the shadow alternatives.
Q: What’s the biggest risk during the training wheels phase?
A: Expanding risk bands without statistical evidence. Organizations often get excited by early wins and prematurely widen auto-apply parameters. Stick to your promotion gates religiously. The second biggest risk is losing explainability—always maintain “Why” panels showing sources and reasoning. Only 27% of organizations review all generative AI outputs before use, creating significant risk exposure.
Q: How do I handle AI hallucinations and errors during pilots?
A: Treat them as valuable telemetry, not failures. Log every error with context, categorize by type (data quality, prompt engineering, model limitation), and use them to improve your guardrails. Most “AI errors” are actually data or process problems that needed fixing anyway. Data quality issues cost the U.S. economy $3.1 trillion annually, making error analysis critical for long-term success.
ROI and Value Measurement
Q: How do I measure ROI when most benefits are efficiency gains, not direct revenue?
A: Use multidimensional metrics: time saved (hours per week), error reduction (% decrease in rework), quality improvement (acceptance rates), and user satisfaction. Convert time savings to dollar values using loaded labor costs. Track leading indicators like edit distance and suggestion acceptance rates alongside lagging indicators like revenue impact. AI search assistants reduce employee search time by up to 1.8 hours per day, providing measurable productivity gains.
Q: When should I expect to see measurable ROI from AI initiatives?
A: Quick wins in efficiency should appear within 30-60 days of co-pilot deployment. Measurable business impact typically emerges 90-180 days post-implementation, once you’ve moved beyond pure suggestions to limited auto-apply. Revenue impact often takes 6-12 months as the compound effects of faster cycles and better decisions accumulate. Organizations implementing revenue intelligence solutions show revenue growth of 83% for AI-using teams vs. 66% for non-AI teams.
Q: How do I justify continued investment if early pilots don’t show immediate ROI?
A: Focus on learning velocity and capability building. Track metrics like time-to-safe-auto-apply, user adoption rates, and process improvements. Frame early phases as infrastructure investment—you’re building the data, governance, and trust foundations that enable future value. Set expectations that ROI comes from scaling successful patterns, not individual pilots. Organizations following portfolio approaches report 3.7x to 10.3x returns on generative AI investments.
Organizational Change
Q: How do I get employees to trust and adopt AI tools?
A: Start with transparency and control. Always show “Why” panels with sources and reasoning. Let users edit and reject suggestions easily. Share success stories and learning from failures openly. Most importantly, make AI tools genuinely helpful for users’ daily pain points, not just management metrics. 79% of organizations have adopted AI agents to some extent, with 96% planning to expand their use.
Q: What skills should I prioritize for reskilling programs?
A: Focus on AI collaboration skills rather than technical AI development. Train people to write effective prompts, evaluate AI outputs critically, understand when to trust vs. verify AI suggestions, and integrate AI tools into existing workflows. Also invest in data literacy and basic understanding of AI capabilities and limitations. New roles are emerging rapidly, including prompt engineers (+135.8% growth) and AI content creators (+134.5% growth)
The Bottom Line for Stakeholders
Training wheels aren’t a bug—they’re the feature. The companies that will win with AI are those that learn systematically from controlled failures, build trust through transparency, and scale responsibility rather than just scale technology.
As one Fortune-quoted executive put it: “Doing nothing because of fear or trying everything because of hype both produce organizational fatigue. Disciplined experiments with visible rules keep teams engaged, safe, and learning.”
However, the 95% “failure” rate isn’t a warning—it’s a map. Follow it with purpose, and you’ll be among the 5% that ride confidently while competitors are still afraid to sit on the bike.
The window for strategic action is narrow—Gartner identifies a critical 3-6 month period for CIOs to define AI strategies before falling behind peers. The organizations that act decisively with proper training wheels will establish lasting competitive advantages.
By 2026, 40% of enterprise apps will feature task-specific AI agents (up from <5% in 2025), and by 2035, agentic AI will drive 30% of enterprise application software revenue ($450+ billion). Organizations that master the training wheels approach today will be positioned to capture this massive value creation opportunity.
One-Liner for Your Teams
“AI drafts and finds; you decide. We’ll widen autonomy only when the data proves it’s safe—especially for pricing and sensitive documents.”
This simple messaging encapsulates the training wheels philosophy: AI as a powerful assistant that enhances human decision-making while maintaining clear boundaries and evidence-based progression toward greater autonomy.
Next Steps with servicePath™
Ready to transform your AI strategy from scattered experiments into systematic competitive advantage? The training wheels methodology isn’t just theory—it’s the proven framework that separates the 5% of AI winners from the 95% who struggle with implementation.
- Read this article
- Book an AI Training Wheels Strategy Session — Design your 90-day roadmap; we’ll assess initiatives, identify high-impact opportunities, and set evidence-based promotion gates
- Guides & Whitepapers — Executive-ready playbooks and frameworks
- Case Studies — Real outcomes: faster cycles, tighter margins, stronger governance
- CPQ Glossary — Enterprise CPQ terms explained, no fluff
- Why servicePath™ is an alternative to Salesforce CPQ — Side-by-side rationale
- Gartner® Recognition — Visionary in CPQ Magic Quadrant™, three years running
- 2025 Recognition News — Details on the latest Magic Quadrant™ placement
- Salesforce CPQ End-of-Sale Explainer — Costs, risks, and the future-proof path
- Explore the AI-Powered CPQ Platform — Deterministic guardrails + probabilistic intelligence, built for complex, changing businesses
This comprehensive guide represents research and insights compiled from multiple authoritative sources on enterprise AI adoption, failure patterns, and success strategies. For the latest updates and strategic guidance on implementing AI training wheels in your organization, visit servicePath™.co.